
Software development is constantly evolving, but developers? They often find themselves stuck in an endless loop:
- Rewriting the same code.
- Fixing the same issues.
- Converting formats over and over again.
It’s like cleaning your room, only to have it messy again the next day! A study by ActiveState has shown that around 40% of a developer’s time is spent on these activities.
This is where Large Language Models (LLMs) come into play, offering an exciting solution for automating code conversion. By understanding and generating code, LLMs help developers save hours of manual effort, strategize problem-solving in new ways, and reduce errors.
With these models advancing rapidly, they’re set to transform how we approach code conversion, unlocking new possibilities for faster and more efficient software development. Let’s explore how LLMs pave the way for a smarter development process and automated code conversions.
Decoding The Problems with Manual Code Conversion
Code conversion involves taking a piece of code written in one language and transforming it into a functionally equivalent version in another language. This task can be complex, especially when the source and target languages have different paradigms or structures. For example, converting Python code to Java requires not just a syntax change but a deep understanding of how each language handles memory management, data types, and object-oriented principles.
Manual code conversion can be tedious and prone to errors. As developers strive to ensure that the translated code works flawlessly, they may overlook small details or introduce bugs that can be hard to trace. This leads to longer development cycles, slower releases, and increased costs.
This is exactly where LLMs step in. They offer a smarter, faster, and more reliable approach to code conversion by leveraging their deep understanding of multiple programming languages and contextual nuances. Let’s explore how LLMs are transforming this process in depth.
What are Large Language Models?
A Large Language Model (LLM) is a type of deep learning model trained on vast datasets to understand and generate human-like language. When applied to code conversion, LLMs enhance speed, accuracy, and accessibility, significantly reducing the time and effort required. In today’s fast-paced tech landscape, migrating from traditional platforms to modernized ones has become increasingly common—whether to improve data retrieval speed, optimize storage by reducing code complexity, or maintain functionality while streamlining the codebase. Thus, leveraging LLMs for code conversion not only accelerates this transition but also ensures greater accuracy and maintainability, making modernization smoother and more efficient.
Various Use Cases of LLMs
LLMs are transforming industries by automating complex tasks, improving efficiency, and enhancing user experiences. Here are some key use cases where LLMs are making a significant impact:
- Clinical Diagnosis: LLMs have significantly improved diagnostic accuracy, reducing errors by 20% and cutting patient waiting times.
- Immediate Assistance for Customers: These models provide instant and precise customer support, enhancing user experience without increasing team size.
- Improving Development Speed and Efficiency: LLMs boost developer productivity by minimizing search time for solutions and accelerating development.
- Translation: They facilitate seamless translation of various materials, including website content, marketing assets, product descriptions, social media posts, customer service documents, and legal contracts.
- Summarization: LLMs quickly condense large volumes of data, extracting key insights from lengthy articles, reports, and documents to aid informed decision-making in a fast-paced environment.
Upgrade to Smarter Code Conversion with LLM Technology. Ready to Take the Leap?
Connect With Us
How are LLMs Transforming Code Conversion
Large Language Models, such as OpenAI’s GPT series and Meta’s Code Llama, are trained on massive code repositories across multiple languages. They leverage this knowledge to provide accurate, context-aware translations. Here’s how they excel:
1. Syntax and Semantics Awareness
LLMs don’t just replace keywords; they understand language-specific syntax and semantics. For instance, they can effectively convert Python list comprehensions into Java streams while maintaining readability and efficiency.
2. Contextual Understanding
Unlike rule-based tools, LLMs can grasp variable scopes, dependencies, and object hierarchies. They ensure that business logic remains intact even when porting to a different language paradigm.
3. Code Optimization and Refactoring
Beyond conversion, LLMs suggest performance enhancements. For example, while converting C++ code to Rust, they may recommend memory-safe practices that align with Rust’s strict ownership model.
4. Multi-language and Framework Adaptability
LLMs support a broad range of languages and frameworks. Whether converting Java to Kotlin for Android development, Python to TypeScript for web applications, or even legacy COBOL to modern Java, LLMs streamline the process.
5. Automated Documentation Generation
Post-conversion, LLMs can generate inline comments, API documentation, and migration guides, making it easier for teams to understand and maintain the new codebase.
In short, LLMs make code conversion faster, more accurate, and less costly, allowing developers to focus on what matters most.
We’ve seen how LLMs revolutionize code conversion, but what happens when they’re put to the test in real-world scenarios? From modernizing legacy systems to bridging programming languages with ease, LLMs are proving to be the ultimate game-changers for developers and businesses alike. Let’s dive into some fascinating use cases where these models turn challenges into breeze.
Use Case 1: Converting SSIS ETL Process (.xml) to Python Equivalent
An XML file that outlines the logic for an ETL process in SQL Server Integration Services (SSIS) can be complex to convert manually into Python. However, with the help of LLMs, this process becomes much simpler—just provide a prompt, and the conversion is done seamlessly.
For Instance:
- If the XML specifies a flat file source, the model can generate Python code to read the file, apply transformations, and write to SQL Server using pyodbc.
- If the XML outlines a flat file destination, the model can automate fetching data from SQL Server, ensure column compatibility, and save the results to a CSV file.
Thus, by using LLMs, developers can focus on improving workflows instead of spending time on tedious configuration conversions.
Use Case 2: Converting T-SQL to Databricks SQL (Query to Query Conversion)
Converting queries from one language to another can be time-consuming, especially when analyzing the source query. For example, transitioning from T-SQL, which is vital for SQL Server, to Databricks SQL, designed for big data environments, can be both tricky and labor-intensive when done manually. While T-SQL is a robust language, Databricks SQL has its own distinct syntax and features optimized for handling large datasets. This requires careful adjustment of scripts to ensure they perform efficiently and effectively in the new environment.
- Grasping SQL Semantics: LLMs comprehend the intent and structure of T-SQL queries and accurately translate them into Databricks SQL, preserving functionality.
- Automating Adjustments: They automatically convert unsupported features like TOP, CROSS APPLY, and OUTER APPLY into equivalent constructs in Databricks SQL, ensuring a seamless transition.
- Minimizing Manual Work: By automating repetitive tasks, LLMs save valuable time and reduce the risk of errors during the migration process.
- Ensuring Precision: LLMs generate consistent, standards-compliant code, minimizing the need for debugging and adjustments post-migration.
- Scaling Migrations: LLMs efficiently handle large-scale migrations, making them ideal for modernizing legacy systems.
With LLMs, developers can overcome SQL migration challenges, accelerate modernization efforts, and ensure a smooth shift to Databricks SQL.
Now let’s have a look at some real-time code snippets
Model Used: Google Gemini
Code Snippet:
import os
from api_tokens import api_keys
from langchain_google_genai import ChatGoogleGenerativeAI
def get_api_keys():
“””
Retrieves the API key from the environment variable or a predefined source.
“””
try:
API_KEY = api_keys()
except Exception as e:
print(“Store the API Key in Environment Variable first”)
print(e)
return API_KEY
def gemini_model():
“””
Initializes and returns the Gemini model using the API key.
“””
model = None
try:
API_KEY = get_api_keys()
print(“API Key retrieved successfully.”)
model = ChatGoogleGenerativeAI(model=”gemini-1.5-pro”, google_api_key=API_KEY)
except Exception as e:
print(f”Problem occurred in fetching API Keys: {e}”)
return model
def prompting(content_read):
“””
Sends a prompt to the Gemini model and retrieves the converted code.
“””
model = gemini_model()
prompt = f”””
***Insert your custom prompt here***
Your Output Format:
:blue[CODESTART] (It is a keyword header)
# Converted code
:blue[CODEEND] (It is a keyword footer)
Output Explanation:
– Strictly don’t mention about the keywords in the output explanation.
“””
try:
response = model.invoke(prompt)
def extract_code(text, start_keyword, end_keyword):
“””
Extracts the code between start and end keywords from the response content.
“””
try:
start_index = text.index(start_keyword) + len(start_keyword)
end_index = text.index(end_keyword, start_index)
code = text[start_index:end_index].strip()
return code
except ValueError:
return “Keywords not found in the text”
result = response.content
code = extract_code(result, ‘:blue[CODESTART]’, ‘:blue[CODEEND]’)
if “\n” in code:
code = extract_code(code, “\ncode”, “\n”)
print(“Result : “, result)
return code, result
except Exception as e:
print(f”Error occurred in retrieving the query: {e}”)
return None, None
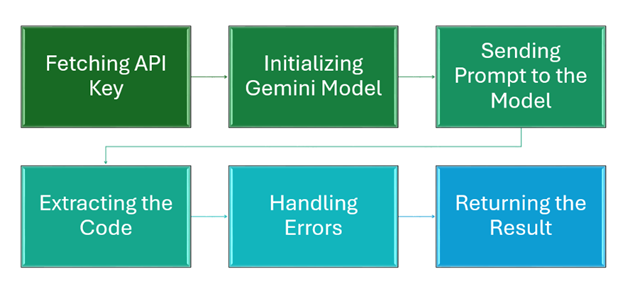
Explanation:
- Fetching the API Key: The function get_api_keys() retrieves the API key. If it fails, the user is prompted to store the key in an environment variable.
- Initializing the Gemini Model: The function gemini_model() initializes the Gemini model using the retrieved API key. If an error occurs, an error message is printed.
- Sending the Prompt to the Model: The prompting() function sends a formatted prompt to the Gemini model. This prompt instructs the model to convert the input content into code.
- Extracting the Code: The extract_code() function extracts the generated code from the model’s response using specific start and end markers (:blue[CODESTART] and :blue[CODEEND]).
- Handling Errors: The code includes error handling to catch issues during the API call, code extraction, or response parsing, providing an error message if something goes wrong.
- Returning the Result: The function returns the extracted code and the model’s full response. If an error occurs, it returns None.
How to Fetch the Gemini API Key:
To obtain a Gemini API key, follow these steps:
1. Visit the Gemini API page.
2. Click “Get API” in Google AI Studio.
3. Sign in to your Google account.
4. Select “Create API Key” in a new or existing project.
5. Click “Copy” to copy the API key.
When creating an API key, you should:
- Treat the API key as you would a password.
- Only share it with trusted entities.
- Set the scope to determine which account the key grants access to.
- Set the role to specify the permissions the key has.
A Few Tips for Front-end
Front-end used:
Streamlit
import streamlit as st
How to upload a file:
uploaded_file = st.file_uploader(“Choose a File“)
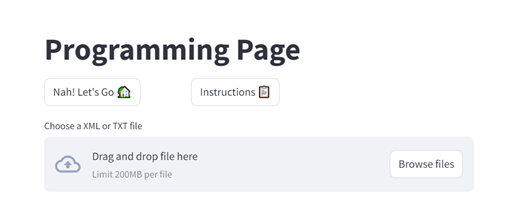
The uploaded file will be stored in the variable uploaded_file
To access the text content of the uploaded file, we need to read it.
if uploaded_file is not None:
try:
content = uploaded_file.read().decode(‘utf-8’)
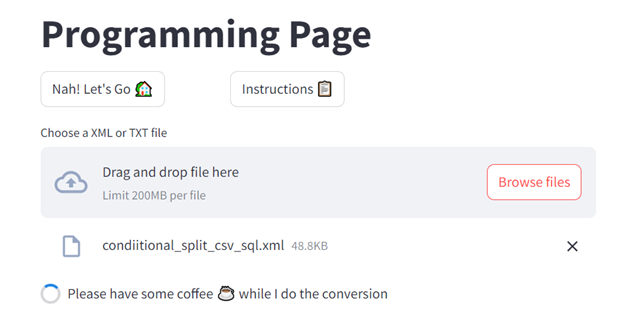
with st.spinner(“Please have some coffee :coffee: while I do the conversion”):
python_code, result = prompting(content)
# Store results in session state
st.session_state.python_code = python_code
st.session_state.result = result
except Exception as e:
st.error(f”An error occurred: {e}”)
st.stop()
Explanation:
- File-Like Object: The uploaded_file behaves like an open file object, allowing you to use methods such as .read() to access the file content.
- Decoding: The .decode(“utf-8”) step converts the file’s binary data into a readable string. If the file uses a different encoding, adjust the encoding accordingly.
- None Check: Always ensure that uploaded_file is not None to prevent errors in case the user has not uploaded a file.
Here’s how the programming page will look like:
Big ideas, bigger possibilities. Explore how LLMs can take your business to the next level!
Explore Service
Real-World Success Story: JPMorgan Chase’s Legacy Code Modernization
JPMorgan Chase, one of the largest financial institutions, faced a significant challenge in modernizing its decades-old COBOL-based banking systems. The bank needed to migrate its legacy code to a modern, scalable, and secure platform while ensuring uninterrupted financial operations.
The Challenge
- COBOL, though reliable, was becoming obsolete, making maintenance costly and time-consuming.
- The bank required a transition to Java for better integration with cloud-based infrastructure.
- Manual migration posed risks of errors, security vulnerabilities, and extensive downtime.
The Solution: LLM-Powered Code Conversion
JPMorgan leveraged LLM-based automated code conversion tools to migrate COBOL programs to Java. The AI-powered system:
- Analyzed legacy COBOL code and understood business logic.
- Converted complex statements into optimized Java code while preserving functionality.
- Suggested improvements, such as refactoring redundant code and enhancing security.
The Outcome
- 60% Faster Migration: Compared to manual conversion, the LLM-powered process significantly accelerated migration.
- 40% Cost Reduction: Lower reliance on COBOL specialists led to reduced maintenance costs.
- Enhanced Performance & Security: The new Java-based system was more scalable, efficient, and aligned with modern cybersecurity standards.
By successfully modernizing its core banking infrastructure using LLMs, JPMorgan demonstrated how AI can transform legacy systems while maintaining business continuity.
Closing Lines
Large language models are changing the game for automated code conversion, helping developers tackle the challenges of updating old systems and switching programming languages more efficiently than ever. By using these powerful tools, businesses can speed up their digital transformation, cut costs, and stay flexible in a rapidly evolving tech landscape.
As AI evolves, the synergy between developers and LLMs will undoubtedly lead to faster, more innovative coding practices, transforming how we build and optimize software.
At Indium, we’re at the forefront of this transformation, offering transformative Gen AI solutions that empower businesses to navigate the complexities of modern technology with ease and efficiency.



